Abstract
Recently, image-based Large Multimodal Models (LMMs) have made significant progress in video question-answering (VideoQA) using a frame-wise approach by leveraging large-scale pretraining in a zero-shot manner. Nevertheless, these models need to be capable of finding relevant information, extracting it, and answering the question simultaneously. Currently, existing methods perform all of these steps in a single pass without being able to adapt if insufficient or incorrect information is collected. To overcome this, we introduce a modular multi-LMM agent framework based on several agents with different roles, instructed by a Planner agent that updates its instructions using shared feedback from the other agents. Specifically, we propose TraveLER, a method that can create a plan to Traverse through the video, ask questions about individual frames to Locate and store key information, and then Evaluate if there is enough information to answer the question. Finally, if there is not enough information, our method is able to Replan based on its collected knowledge. Through extensive experiments, we find that the proposed TraveLER approach improves performance on several VideoQA benchmarks without the need to fine-tune on specific datasets.
Overview
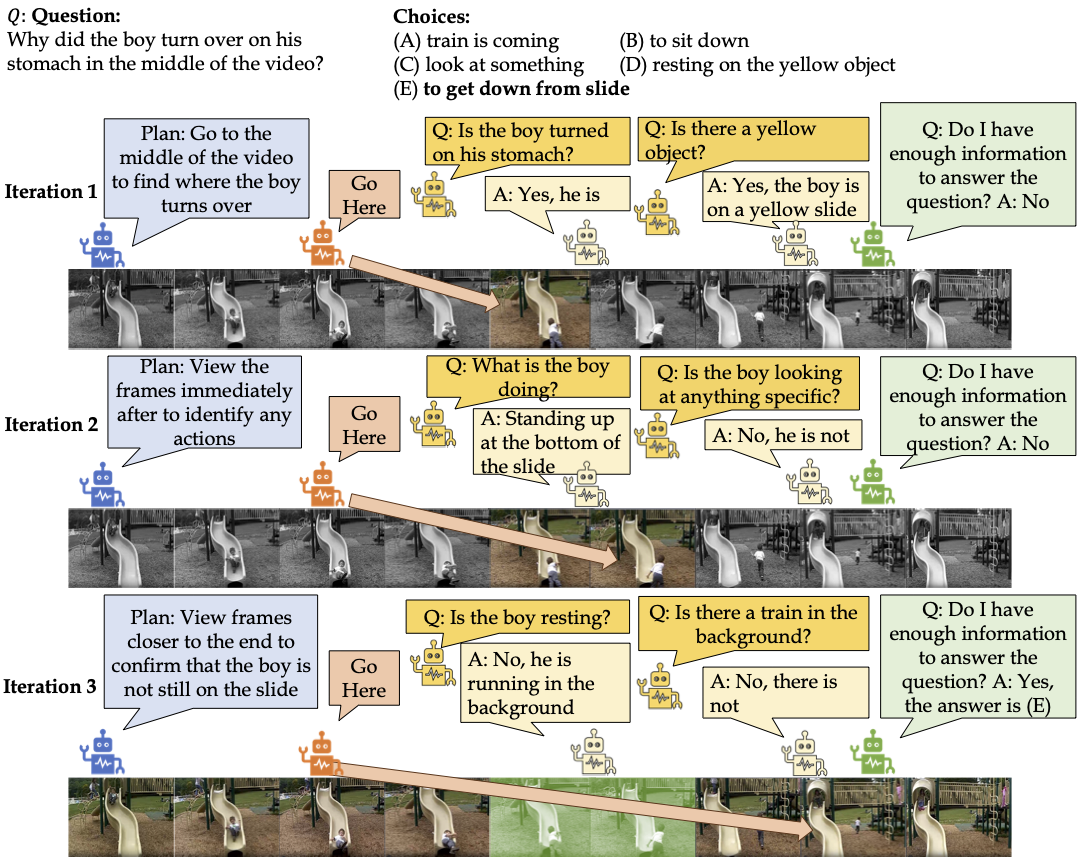
Our proposed framework aims to answer the question by collecting relevant information from keyframes through interactive question-asking. To accomplish this, several agents (in colored boxes) with different roles interact (left-to-right in each row) over several iterations. TraveLER creates a plan (in blue) to “traverse” (in orange) through the video, asks questions regarding individual frames (in yellow) to “locate” and store key information and, “evaluates” whether there is sufficient information to answer the question (in green), and “replans” using past collected knowledge if there is not enough information.
Framework
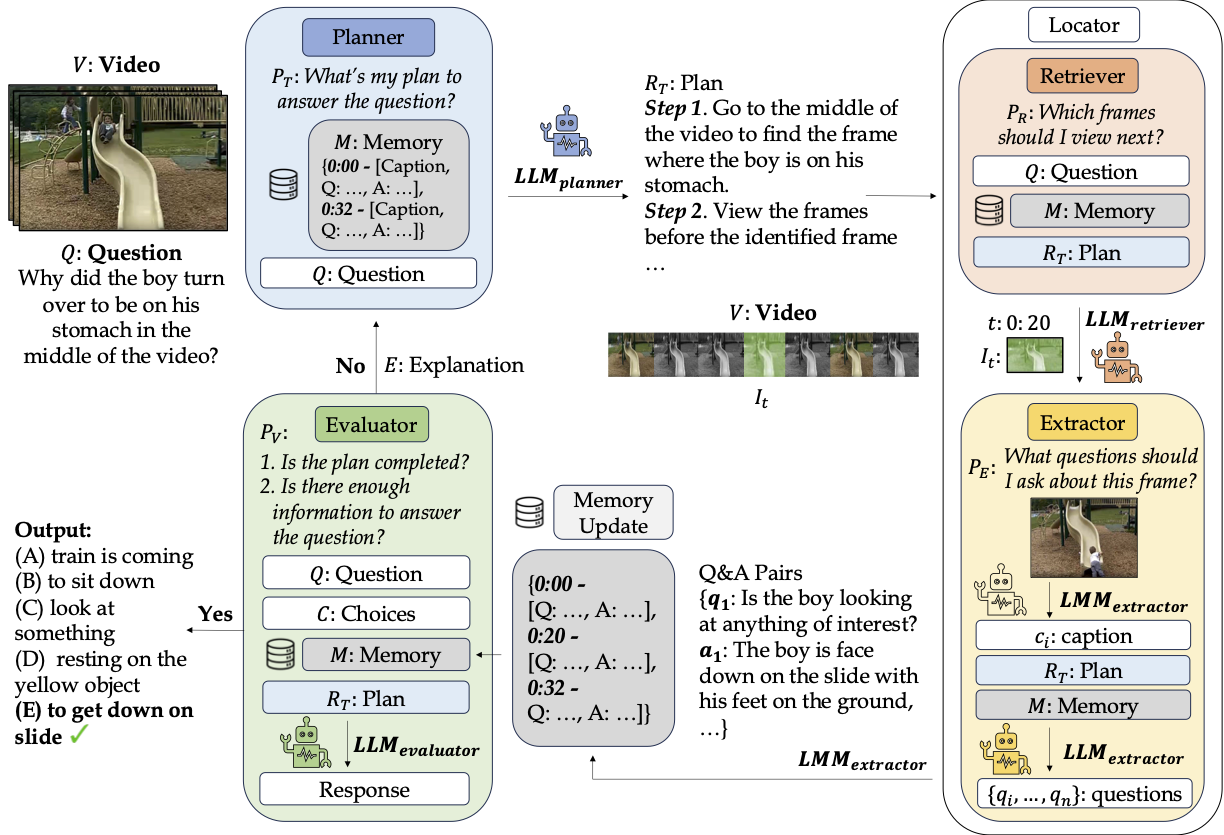
Our framework consists of four different modules, the Planner, Retriever, Extractor, and Evaluator. The Planner creates a plan and sends it to the Retriever. The Retriever uses the plan to select the next timestamp and sends this to the Extractor. The Extractor captions and generates questions about the timestamp, answers the questions, and saves the output in the memory bank. Finally, the Evaluator determines if there is enough information and if the plan has been followed. If yes, the Evaluator returns the answer, else the existing information is sent back to the Planner to begin a new iteration.
📊 Results
Benchmarks
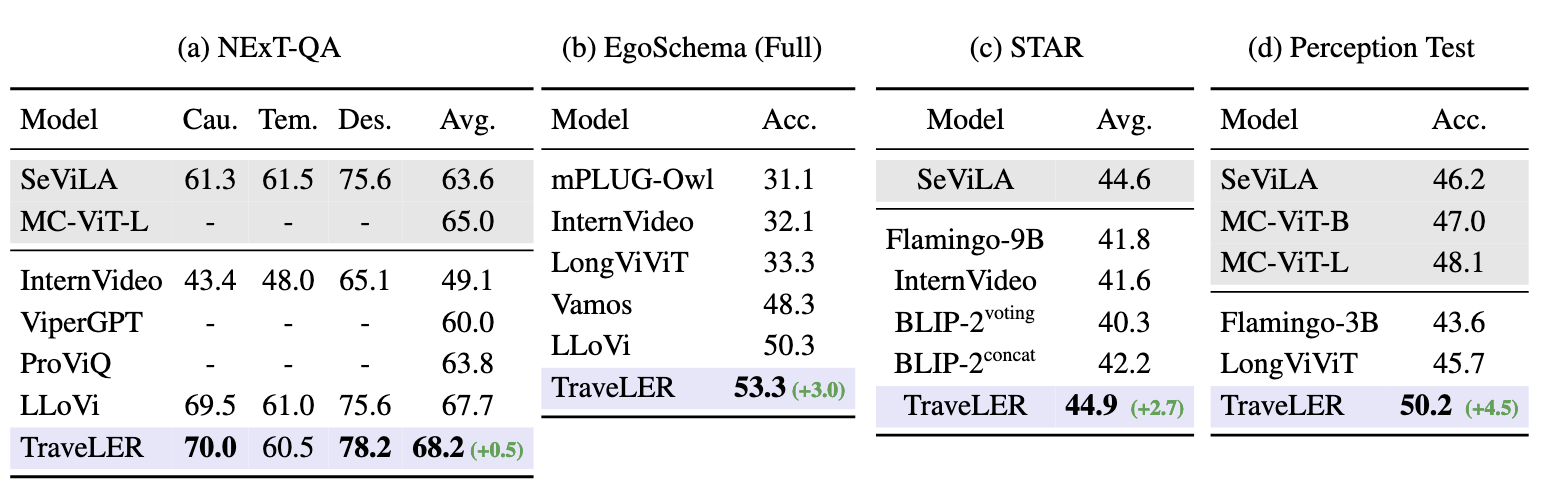
TraveLER achieves state-of-the-art (SOTA) zero-shot results on a variety of VideoQA datasets, including NExT-QA, EgoSchema, STAR, and Perception Test. Our method often outperforms other approaches despite viewing fewer frames on average, or outperforms some fine-tuned approaches even when our method is zero-shot.
Ablations
Our modular approach has the benefit of allowing us to easily swap in different LLMs and LMMs. We perform ablations on 1000 randomly selected questions from the NExT-QA training set. We report (a), (b) replacing different LLMs and LMMs, (c) selecting different numbers of frames to view in the Retriever, and (d) changing the number of questions asked in the Extractor.
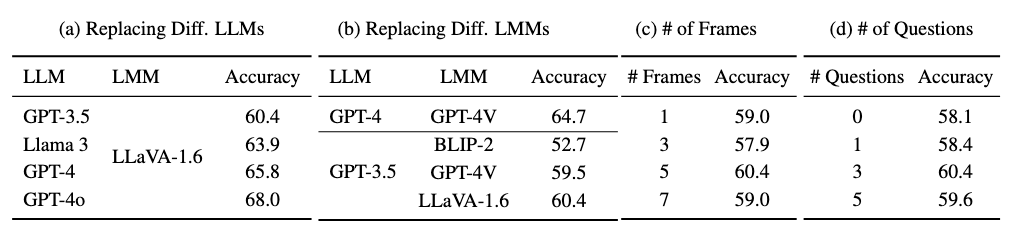
We find that the performance of TraveLER improves as we swap in more sophisticated LLMs and LMMs, and we expect this trend to continue for future models. We discover that the optimal settings for the Retriever is to view a window of 5 frames each iteration, and for the Extractor to ask 3 questions at a time.